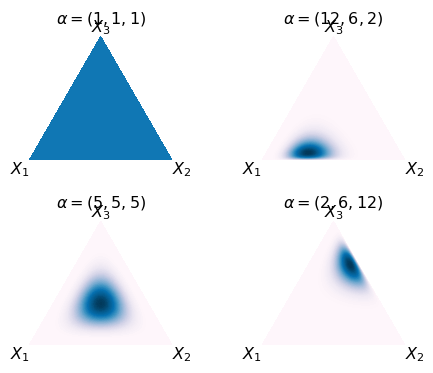
Discrete Distribution Family
Multivariate discrete distribution
Illustration of Dirichlet Prior
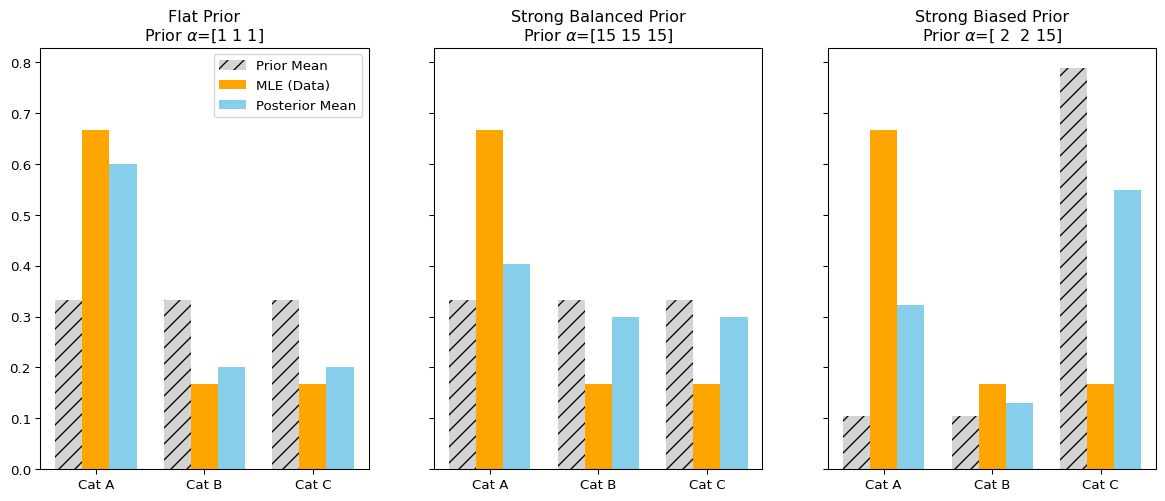
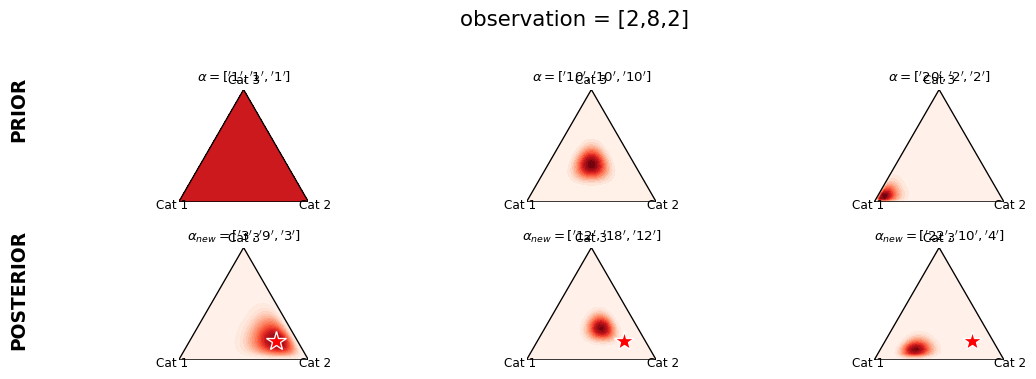
Dirichlet prior adds a psuedo \(\alpha\) observations. (The observed data is [8,2,2])
Illustration
Thep posterior distribution has the kernel (functional form) of a Dirichlet distribution with updated parameters \(\mathbf{\alpha}'\):
\[ \begin{aligned} \mathbf{\alpha}' = (\mathbf{\alpha} + \textbf{x}) = (\alpha_1 + x_1, \alpha_2 + x_2, \dots, \alpha_K + x_K) \end{aligned} \]
Interpretation: The \(\alpha_i\) values act as “imaginary” observations seen before the experiment.
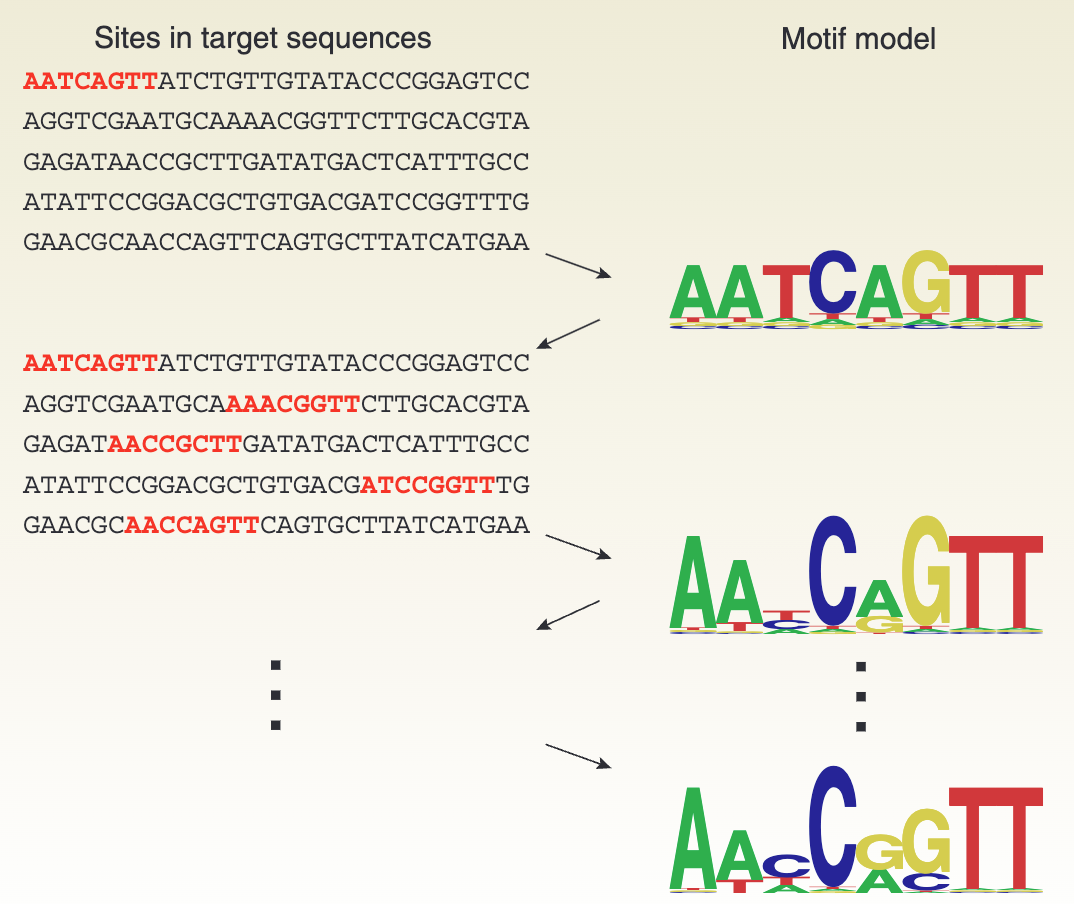
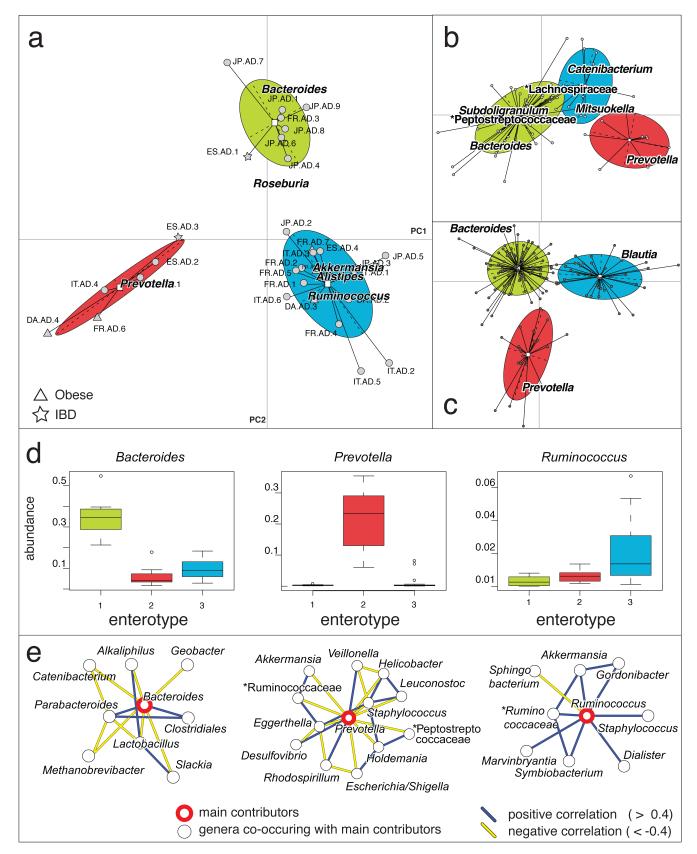
Application in bioinformatics
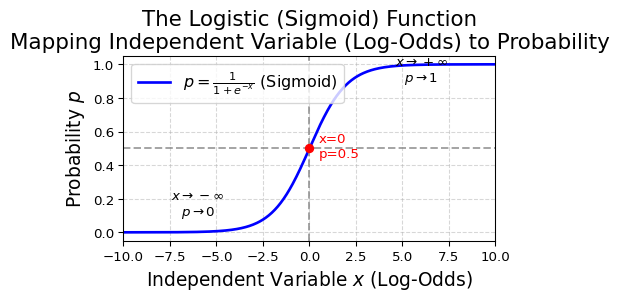
Logistic regression
In logistic regression (binomial outcomes), the link function is
Logit link function
\[
\log\frac{p(x)}{1-p(x)}=\alpha+\beta x
\]
Transform them back to get \(p(x)\)
\[ p(x)=\frac{e^{\alpha+\beta x}}{1+e^{\alpha+\beta x}} \]
For a dichotomous predictor \(x\) with values 0 and 1, \(\beta\) is the log odds ratio (\(\log(\text{OR})\)).
Discussion: if we model \(p(x)=\alpha+\beta x\), is it causing any trouble?
- Potential estimate for \(p(x)>1\) or \(p(x)<0\)
Ordinal logistic regression
Illustration: \(\alpha_{-1}=-3,\alpha_{0}=2, \beta=1.5\)
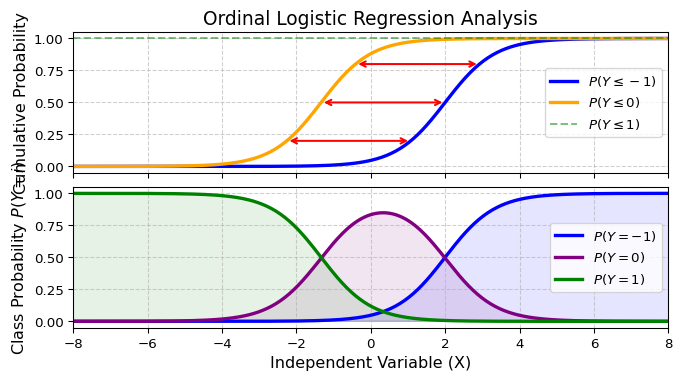
Implications
- Finding cut-offs for different ordinal outcomes
- If we extend to really continuous case, then we do not need that cut-offs to specific class